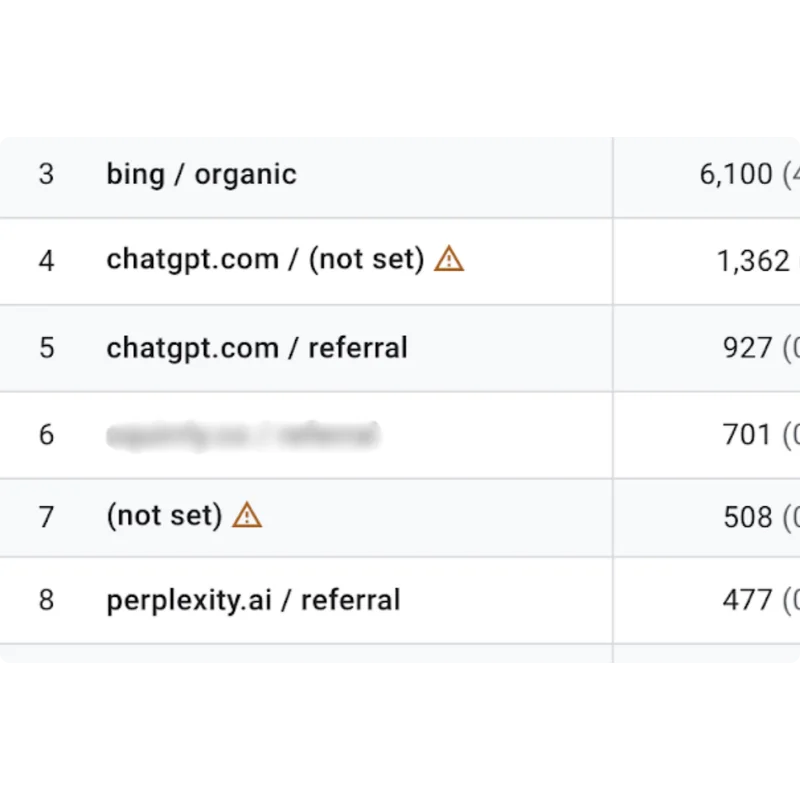
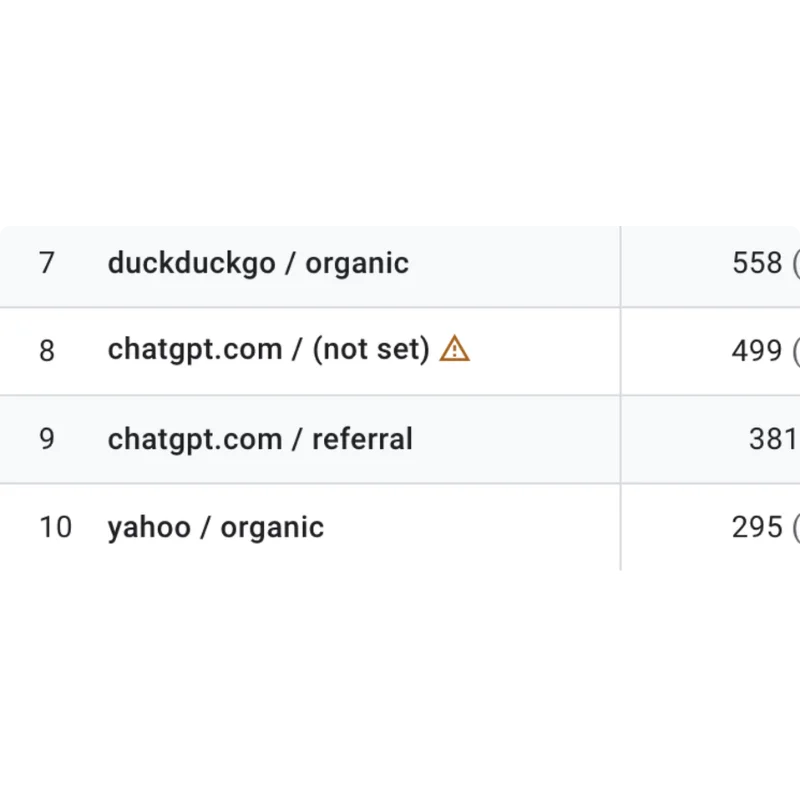
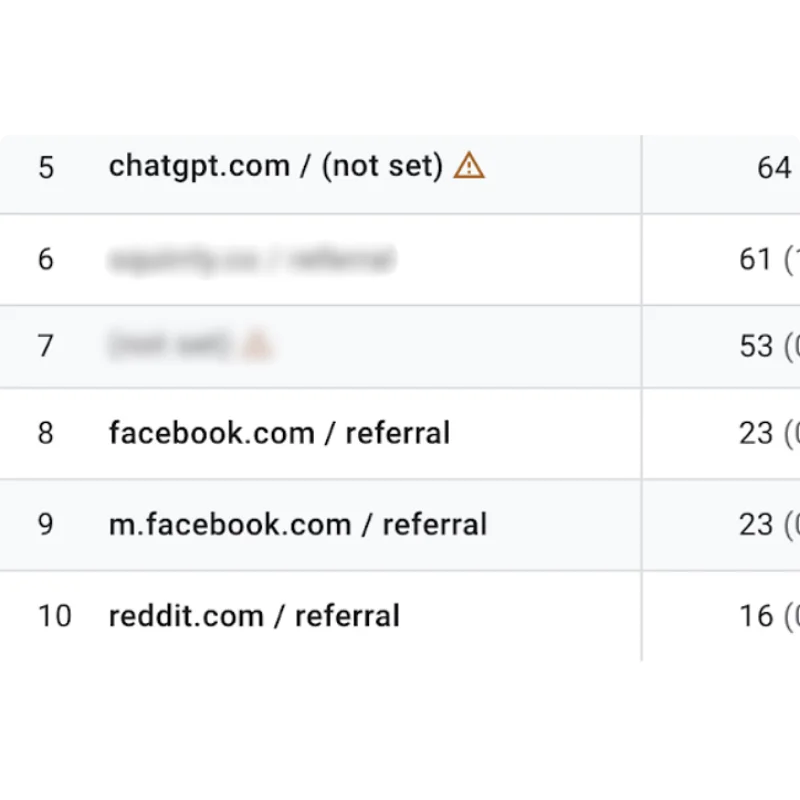
Robots.txt File Settings

The robots.txt file is a text file that tells search engine crawlers which pages on your site to crawl – and which pages NOT to crawl.
Your robots.txt file will always live at this address: your site/robots.txt
What search engines crawlers should find in your Robots.txt file is:
- a list of sitemaps (Squirrly adds this information automatically based on the post types for which you’ve activated a sitemap)
- Disallow rules (this tells search engine crawlers what NOT to crawl from your site)
- Allow rules (this tells search engine crawlers what to crawl from your site)
What’s the point in telling search engine robots NOT to crawl certain pages or files?
“You don’t want your server to be overwhelmed by Google’s crawler or to waste crawl budget crawling unimportant or similar pages on your site.”
Yes, Google has a crawl budget which is basically made of “the number of URLs Googlebot can and wants to crawl.” By using your robots.txt the right way, you can help Googlebot spend its crawl budget for your site wisely (meaning: by crawling your most valuable pages).
Now that you know a bit more about what makes the robots.txt file so useful in an SEO context, let’s see what you can do in the Robots File section of Squirrly.
How to Access Robots File
The Robots.txt file settings are located within the SEO Configuration section of Squirrly SEO. Navigate to Squirrly SEO > Technical SEO > Tweaks & Sitemap > Robots file in order to reach it.
You can activate / Deactivate Robots.TXT by sliding the toggle right (to activate) or left (to deactivate) – from the All Features section of Squirrly.
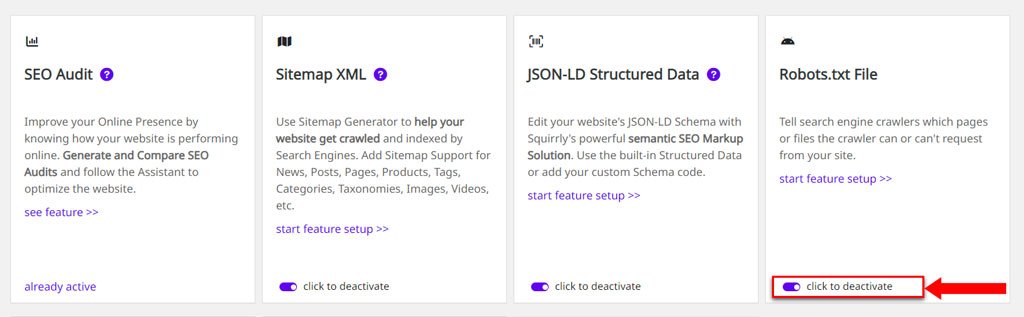
By default, this is set to ON. We recommend leaving this on, as the robots.txt file is important in an SEO context.

Default Robots Code
- To reach this section, go to: Squirrly SEO > Technical SEO > Tweaks & Sitemap > Robots File > Edit the Robots.txt data
In the images below, you can see how the default code for robots.txt looks like.
We recommend leaving this as is if you are not an SEO expert and are just starting to understand what the robots.txt file is all about.

User-agent: * Disallow: */trackback/ Disallow: */xmlrpc.php Disallow: /wp-*.php Disallow: /cgi-bin/ Disallow: /wp-admin/ Allow: */wp-content/uploads/
This is an example of how the code appears in: site name/robotx.txt.

* Does not physically create the robots.txt file. The best option for WP Multisites.
Custom Robots Code: Edit the Robots.txt data
- To reach this section, go to: Squirrly SEO > Technical SEO > Tweaks & Sitemap > Robots File > Edit the Robots.txt data
Squirrly gives you the option to edit and customize the Robots.txt data, allowing your to add your own rules.
However, make sure to edit the Robots.txt ONLY if you know what you’re doing. Adding wrong rules in Robots can lead to SEO ranking errors or block your posts in Google.
^^ Alternatively, you can use the SEO Automation rules and place no-index on certain post-types, or at individual page levels, to ensure better control and logic control over the Robots.txt file.